First of all: Hopefully this is the correct thread for this issue.
For about a few weeks i´ve got the problem that one container only worked “a bit”. Its hard to describe this error.
When two specified container where running, one was very slow while answering.
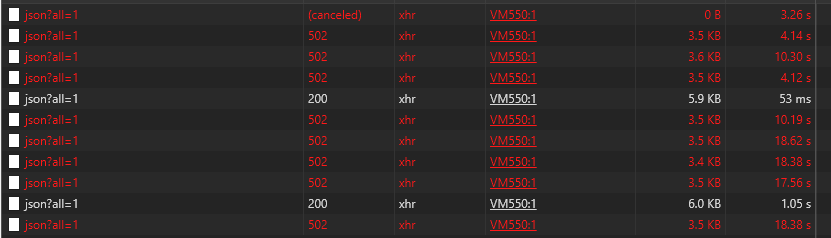
Now, the “problem” container ist offline and for example the Portainer container ist answering only 1 in 5 times. (See Picture below)
Thank you for this fast response.
I´ve updated the nginx configuration as mentioned in your thread but this didn´t work.
I´ve found out that it has to do with the networking itself.
The bridge seems not to work properly
PING 172.17.0.3 (172.17.0.3) 56(84) bytes of data.
From 172.17.0.5 icmp_seq=39 Destination Host Unreachable
64 bytes from 172.17.0.3: icmp_seq=59 ttl=64 time=0.018 ms
From 172.17.0.5 icmp_seq=56 Destination Host Unreachable
From 172.17.0.5 icmp_seq=60 Destination Host Unreachable
From 172.17.0.5 icmp_seq=63 Destination Host Unreachable
64 bytes from 172.17.0.3: icmp_seq=67 ttl=64 time=0.038 ms
64 bytes from 172.17.0.3: icmp_seq=69 ttl=64 time=0.028 ms
64 bytes from 172.17.0.3: icmp_seq=72 ttl=64 time=0.020 ms
64 bytes from 172.17.0.3: icmp_seq=73 ttl=64 time=0.023 ms
From 172.17.0.5 icmp_seq=76 Destination Host Unreachable
64 bytes from 172.17.0.3: icmp_seq=81 ttl=64 time=0.029 ms
From 172.17.0.5 icmp_seq=79 Destination Host Unreachable
From 172.17.0.5 icmp_seq=80 Destination Host Unreachable
64 bytes from 172.17.0.3: icmp_seq=82 ttl=64 time=0.028 ms
From 172.17.0.5 icmp_seq=83 Destination Host Unreachable
From 172.17.0.5 icmp_seq=86 Destination Host Unreachable
64 bytes from 172.17.0.3: icmp_seq=89 ttl=64 time=0.029 ms
64 bytes from 172.17.0.3: icmp_seq=90 ttl=64 time=0.019 ms
64 bytes from 172.17.0.3: icmp_seq=91 ttl=64 time=0.019 ms
It seems that the routing is failing.
Working test
traceroute 172.17.0.3
traceroute to 172.17.0.3 (172.17.0.3), 30 hops max, 60 byte packets
1 172.17.0.3 (172.17.0.3) 0.208 ms 0.157 ms 0.145 ms
I found out that the MAC Address has been assigned multiple times.
After recreating the container with a manually configured MAC Address everything worked properly.
But why is docker assigning an already taken MAC Address to a new container (created by docker run)?
Do their indexes Start at 1 when checking existing mac addresses?
My new container got the MAC Address from the first host listed in docker network inspect bridge
I´ve added a github issue on this.
My workaround: ive deleted the container and added it with a manually configured mac address