I am trying to dockerize my ingest data python script in Git Bash, but when I try to run it in docker I get the error of “output.parquet” not found. Even though when I run the python script without docker such as “python ingest_data.py” it runs perfectly and loads the data to pgAdmin. Does anyone know how to resolve this issue concerning dockerizing my python script and having it run to populate pgAdmin with data?
Good morning and welcome,
please do not use absolute windows-style-paths within your container to open your files.
For linux-style-containers (as I use on my Docker-installation on Windows) I have to use Linux-style paths or better use relative paths.
For windows-style-containers I have no idea how the paths should be.
Of course please ensure that the file output.parquet is available within the container: either is is already bundled within the container or you mount it from a docker-volume or your local drive into the container.
Good morning,
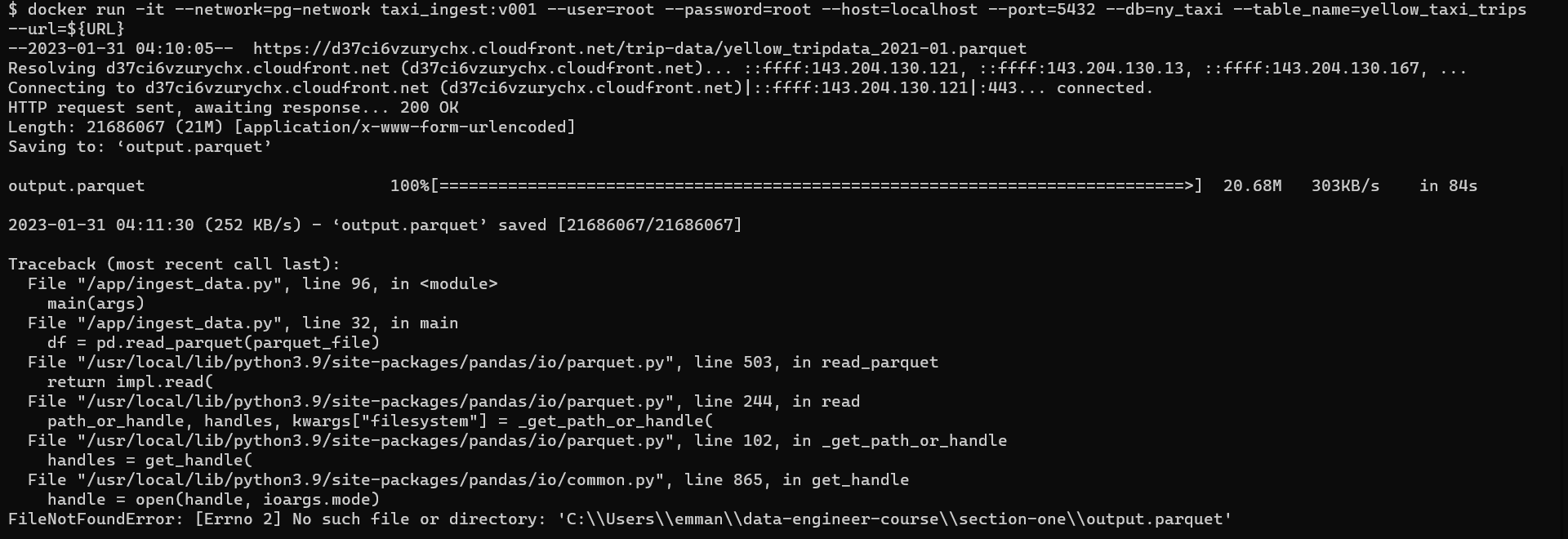
I have updated my python script ingest_data.py to be Linux-style-paths, and my ingest_data.py file is using the wget command in order to read a parquet file from a website so I am unable to mount it on my local drive due to it not existing until ingest_python.py is run. I have included update error messages, dockerfile, and ingest_data.py to help with debugging.



Sorry for not clarifying what I meant with “linux-style-paths”. My mistake ![]()
From the Dockerfile I can see that your workdir is /app/ so your wget runs within this path and writes the output.parquet to this directory.
Later you try to read from a path C:/...../output.parquet which will not work because this path is not available within the container and the file you really want to read is at /app/output.parquet.
So I would try to skip using the variable parquet_file and directly use parquet_name. The same is for the variable csv_output and csv_name.
Another thing I am wondering about is: why is there a f-string for the wget-command and the postgresql-url but a fr-string for parquet_file and csv_output?
Thank you so much my dockerfile was able to run successfully!
To answer your question as to why fr-string is used for parquet_file and csv_output, it is because I saw it on a youtube video on how to convert a parquet file into a csv file. The set up the originally had was something like this ( parquet_file = r’C:/…/output.parquet’ ). I changed it to use a variable name instead of raw data, and I know ‘f-string’ allows me to do that. So I thought ( parquet_file = fr’C:/…/output.parquet’ ) would suffice, but is that good programming practice? I realize now that upon looking at wget-command and the postgresql-url they worked fine with just f-string, so do I do the same for parquet_file and csv_output?
Again thank you so much for the help!

As I am not a Python-programmer (at least not yet ![]() ) I am not sure about the correctness/completeness of the following answer:
) I am not sure about the correctness/completeness of the following answer:
-
r-strings are raw-strings which mean that escape-characters are ignored. Therefore the content
C:\...\...\output.parquetworked even if the single backslash is normally used as the escape-character. -
f-strings on the other hand are used for inserting variables into literal strings using the curly brackets
{...}. - rf-strings therefore are a combination of both: escape-characters are ignored and variables are replaced with their content.
As you aure using linux-paths working without the backslash there is no need for this r - but on the other hand it doesn’t hurt ![]() .
.